
by Dr. Reynold Cheng (ckcheng@cs.hku.hk)
Introduction
In
applications such as location-based services, natural habitat monitoring, web
data integration, and biometric applications, the values of the underlying data
are inherently noisy or imprecise. Consider a location-based application that
provides querying facilities on geographical objects (e.g., airports, vehicles,
and people) extracted from satellite images. Due to the errors incurred during
satellite image transmission, the locations of the geographical objects can be
imprecise. The data acquired from the Global Positioning System (GPS) and
remote sensors can also be inaccurate and outdated, due to measurement error
and network delay. As another example, consider a movie
rating database integrated from WWW sources (e.g., IMDB movie database
and user ratings obtained from the Netflix
challenge). Due to the difference in the movie names specified in the sources
(e.g., a user may type a wrong movie name), the integrated database may not be
completely accurate. In biological applications, the extent of the area of a
retina cell extracted from microscopy images can be inexact, due to limited image
resolution and measurement accuracy.
In order to satisfy the increasing needs of the above applications, we envision that novel, correct, and scalable methods for managing uncertain data need to be developed. To achieve this goal, our research group is working on two projects:
Project 1: Develop a practical database system that incorporates uncertain data as a first-class citizen, in order to facilitate the development of the above applications; and
Project 2: Investigate the issues of data uncertainty in data mining, ambiguity removal, and data integration.
The following describes how we approach these goals, and a summary of our current results.
Project 1: Designing an Uncertain Database
System
 |
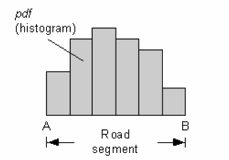 |
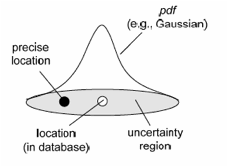
| (a) Location Uncertainty (Gaussian pdf) | (b) Location uncertainty of a vehicle in a road network (arbitrary pdf) |
Figure 1: Attribute uncertainty.
To
handle the increasing needs of managing a large amount data, our goal is to
develop an uncertain database system, which incorporates uncertain data as a
"first-class citizen". This means that the database system should provide
handy ways of modeling uncertainty, as well as enable querying facilities,
which return imprecise answers to users with statistical guarantees.
The
ORION database system, which we
co-developed with Purdue University in 2006, provides some of these features.
For example, it supports the modeling of attribute
uncertainty, which is essentially a range of possible values, together with
their probability density functions (pdf). This
model, as illustrated in Figure 1, is widely used in location-based
applications, road networks, sensor networks, and biological applications. The
ORION system also provides querying facilities on uncertain data. In
particular, it supports the evaluation of probabilistic
queries, which augments statistical guarantees on query answers. For
instance, if we want to know which sensor in a geographical area yields a
temperature between 10°C and 30°C, then a probabilistic query returns answers
like: {(A, 0.1), (B, 0.8)}, meaning that sensors A and B collect temperature readings between 10°C and 30°C, with
probabilities 0.1 and 0.8, respectively. The technical results about this system can be found here.
 |
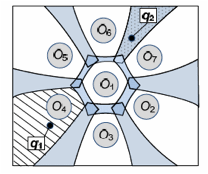 |
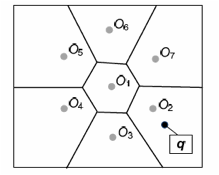
| (a) The Voronoi Diagram | (b) The UV-diagram |
Figure 2: The Voronoi Diagram and the UV-diagram.
Since obtaining probabilities can be expensive, a probabilistic query can be slow to execute. To address this problem, we develop efficient and scalable query execution algorithms. We studied the evaluation of probabilistic range queries. We also developed the computation of the probabilistic nearest-neighbor (NN) query, which allows questions like: "Which restaurant in Hong Kong is the closest to me?" to be answered. We examined two variants of NN:
(1) snapshot NN (i.e., the query is issued only once); and
(2) continuous NN query (i.e., the query is executed for an extensive amount of time).
Recently, we have proposed the Uncertain Voronoi diagram (or UV-diagram in short). The UV-diagram is a generalization of the Voronoi diagram, which facilitates NN query evaluation, for uncertain data. Figures 2(a) and (b) illustrate the Voronoi diagram (for seven precise data points) and the UV-diagram (for seven location uncertain data items). For both diagrams, answering a NN query involves finding the Voronoi cell that contains the query point (i.e., q, q1, and q2). Notice that in a UV-diagram, a Voronoi cell can be associated with two or more objects (e.g., q2 is located in a region where both O6 and O7 can be the closest to it). Since the UV-diagram is expensive to be constructed and stored, we propose a new data structure, called the UV-index, which resembles the UV-diagram. We study how the UV-index can be efficiently constructed and used to answer NN queries. We also plan to incorporate the UV-index into the ORION.
Grant Support
1. UV-Diagram: A Voronoi Diagram for Uncertain Spatial Databases (RGC GRF, Ref: 711110, 2011-13). HKD 746,400.
2. Scalable Continuous Query Processing on Imprecise Location Data (RGC GRF, Ref: 513508, 2009-10). HKD 645,950.
3. Adaptive Filters for Continuous Queries over Constantly-Evolving Data Streams (RGC GRF, Ref: 513307, 2008-09). HKD 391,512.
Selected Publications (Click
here for a full list)
1. R. Cheng, X. Xie, M. Y. Yiu, J. Chen, and L. Sun. UV-diagram: A Voronoi Diagram for Uncertain Data. In the IEEE Intl. Conf. on Data Engineering (IEEE ICDE 2010), Long Beach, USA, Mar, 2010 (Full paper). Acceptance rate: 12.5%. [Paper][Talk]
2. J. Chen, R. Cheng, M. Mokbel and C. Chow. Scalable Processing of Snapshot and Continuous Nearest-Neighbor Queries over One-Dimensional Uncertain Data. In Very Large Databases Journal (VLDBJ), Special Issue on Uncertain and Probabilistic Databases, Vol. 18, No. 5, pp. 1219-1240, 2009. (Awarded the Research Output Price in Department of Computer Science, Faculty of Engineering, HKU, 2010) [Paper]
3. J. Chen and R. Cheng. Efficient Evaluation of Imprecise Location-Dependent Queries. In the IEEE Intl. Conf. on Data Engineering (IEEE ICDE 2007), Istanbul, Turkey, Apr, 2007. Acceptance rate: 18.5%. [Paper][Talk]
4. R. Cheng, B. Kao, S. Prabhakar, A. Kwan and Y. Tu. Adaptive Stream Filters for Entity-based Queries with Non-value Tolerance. In Very Large Databases Conf. (VLDB 2005), Norway, Aug 2005, pp. 37-48. Acceptance rate: 16.5%. [Paper]
5. R. Cheng, D. Kalashnikov and S. Prabhakar. Evaluating Probabilistic Queries over Imprecise Data. In Proc. of the ACM Special Interest Group on Management of Data (ACM SIGMOD 2003), pp. 551-562, June 2003. Acceptance rate: 15.2%, 52/342. [Paper][Talk]
Project 2: Uncertainty and Database Applications
As discussed before, uncertainty is prevalent in many important applications. In this project, we focus on three major areas, namely, ambiguity removal, uncertain data mining, and data integration.
|
|
|
|
(a) A probabilistic database. |
(b) A partially cleaned database (for (a)). |
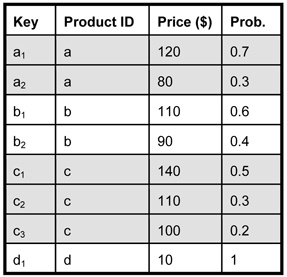
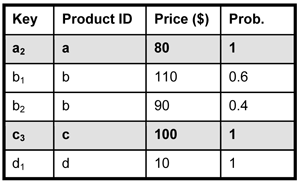
Figure 3: Cleaning a probabilistic database.
• Ambiguity Removal: We study the issues
of improving service quality on a probabilistic database. In many applications,
service quality can be enhanced by "cleaning" these databases.
Consider a probabilistic database used to record the price of products
integrated from different web sources (Figure 3(a)). The uncertainty about
these ratings can be "sanitized" (or cleaned) by manually contacting the
respective users for clarification (Figure 3(b)). In a location-based
application that stores the current positions of mobile objects (e.g., people
and vehicles) in a probabilistic database, the system can clean the database by
requesting the mobile objects to report their most-updated location values (and
replace the outdated ones in the database). Cleaning thus reduces the ambiguity
of the probabilistic database, as well as improving the quality of the queries
that are evaluated on it.
In
this work, we plan to develop a sound and universal metric to quantify the
quality of query answers. We design efficient algorithms that select the most
appropriate set of objects to be cleaned. Since cleaning involves costs (e.g.,
energy/network bandwidth for data transmission, or manpower used to validate
the data), these algorithms have to be performed under a limited cleaning
budget. A cleaning engine, illustrated in Figure 4, is being developed on top of an
open-source probabilistic database.
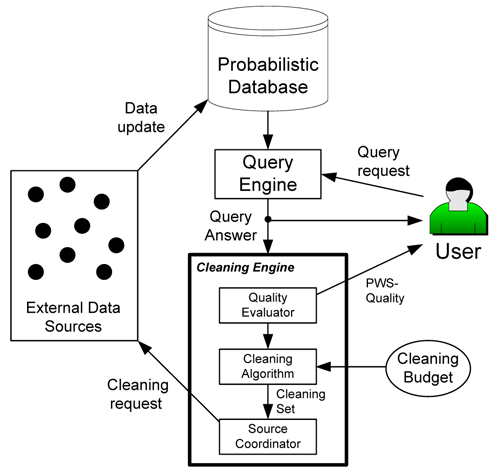
Figure 4: A probabilistic database cleaning system.
• Uncertain Data Mining: We study the issues of
developing data mining algorithms (e.g., frequent pattern and classification)
for probabilistic databases, which contain a vast amount of interesting
information. Discovering frequent patterns and association rules from these
data is technically challenging, since a probabilistic database can have an
exponential number of possible worlds. We propose two efficient algorithms,
which discover frequent patterns in bottom-up and top-down manners. Both
algorithms can be easily extended to discover maximal frequent patterns. To
achieve higher efficiency, we also examine an approximate (but highly accurate)
version of frequent pattern mining. We address the issues of using these patterns
to generate association rules. Extensive experiments, using real and synthetic
datasets, were conducted to validate the performance of our methods.
• Data integration: Despite of advances
in machine learning technologies, a schema matching result between two database
schemas (e.g., those derived from COMA++) is likely to be imprecise. In
particular, numerous instances of "possible mappings" between the schemas may
be derived from the matching result. In this project, we study the problem of
managing possible mappings between two heterogeneous XML schemas. We observe
that for XML schemas, their possible mappings have a high degree of overlap. We
hence propose a novel data structure, called the block tree, to capture the
commonalities among possible mappings. The block tree is useful for
representing the possible mappings in a compact manner, and can be generated
efficiently. Moreover, it supports the evaluation of probabilistic twig query
(PTQ), which returns the probability of portions of an XML document that match
the query pattern. For users who are interested only in answers with k-highest
probabilities, we also propose the top-k PTQ, and present an efficient solution
for it.
The
second challenge we have tackled is to efficiently generate possible mappings
for a given schema matching. While this problem can be solved by existing
algorithms, we show how to improve the performance of the solution by using a
divide-and- conquer approach. An extensive evaluation on
realistic datasets show that our approaches significantly improve the
efficiency of generating, storing, and querying possible mappings.
Grant Support
1. Scalable Cleaning of Probabilistic Databases with Quality Guarantees (RGC GRF, Ref: 711309E, 2010-12). HKD 696,500.
2. Privacy Protection in Location-based Services with Location Cloaking (RGC CERG. Ref: 513806, 2007-09). Amount: HKD 356,000 (Completed).
Selected Publications (Click
here for a full list)
1. R. Cheng, E. Lo, X. Yang, M. Luk, X. Li, and X. Xie. Explore or Exploit? Effective Strategies for Disambiguating Large Databases. In Very Large Databases Conf. (VLDB 2010), Singapore, Sep, 2010. [Paper]
2. L. Sun, R. Cheng, D. W. Cheung, and J. Cheng. Mining Uncertain Data with Probabilistic Guarantees. In the 16th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining (ACM SIGKDD 2010), Washington D.C., USA, Jul, 2010 (Full paper). Acceptance rate: 17%. [Paper]
3. L. Wang, D. Cheung, R. Cheng, and S. Lee. Accelerating Probabilistic Frequent Itemset Mining: A Model-Based Approach. In the ACM 19th Conf. on Information and Knowledge Management (ACM CIKM 2010), Toronto, Canada, Oct 2010. Acceptance rate: 13.4%
4. R. Cheng, J. Gong, and D. Cheung. Managing Uncertainty of XML Schema Matching. In the IEEE Intl. Conf. on Data Engineering (IEEE ICDE 2010), Long Beach, USA, Mar, 2010 (Full paper). Acceptance rate: 12.5%. [Paper][Talk]
5. R. Cheng, J. Chen, and X. Xie. Cleaning Uncertain Data with Quality Guarantees. In Very Large Databases Conf. (VLDB 2008), New Zealand, Aug 2008. Acceptance rate: 16.5%. [Paper][Talk]
Contact: For
more information, please contact Dr. Reynold Cheng.