
Human analysis is of wide interest in the research community of computer vision and artificial intelligence (AI), such as recognizing human facial identities, expressions and emotions, as well as human behaviours like poses, actions, events, social relationships from images and videos. As humans have a very significant role to play in any AI system, understanding human’s behaviours advances human-AI paired systems that outperform their singular counterparts. To facilitate the understanding of various human behaviours, an AI system should possess the capability of figuring out the semantic meaning of each small region an image. As an image may have more than hundreds of thousands of pixels, an important goal of human analysis is to extract useful information of high-level semantic concepts. For example, various factors such as identity, view, and illumination, are coupled in human face images. Disentangling the identity and view representations is a major challenge when recognizing human faces. Another example is whole-body human pose estimation, which aims at localizing key points of body, face, hand, and foot simultaneously, being important for the development of downstream applications such as virtual reality, augmented reality, human mesh recovery, and action recognition.
A LSTM Model for Human Motion Prediction
Inspired by the Long Short-Term Memory (LSTM) model that learns temporal dependency of sequential data, we built a machine vision system [1] that can predict walking directions and trajectories of multiple agents (pedestrians), which is important for many real-world applications such as self-driving vehicle, traffic surveillance, and autonomous mobile robot. Different from existing work that either model agents’ interactions or the scene layout, we carefully designed novel mechanisms in LSTM to model dynamic interactions of pedestrians in both spatial and temporal dimensions, as well as modelling the semantic scene layout as latent probabilistic variable to constrain the predictions. These design principles enable our model to predict multiple trajectories for each agent that cohere in time and space with the other agents as shown in Figure 1.

The research works were done by Dr. Luo Ping's group.
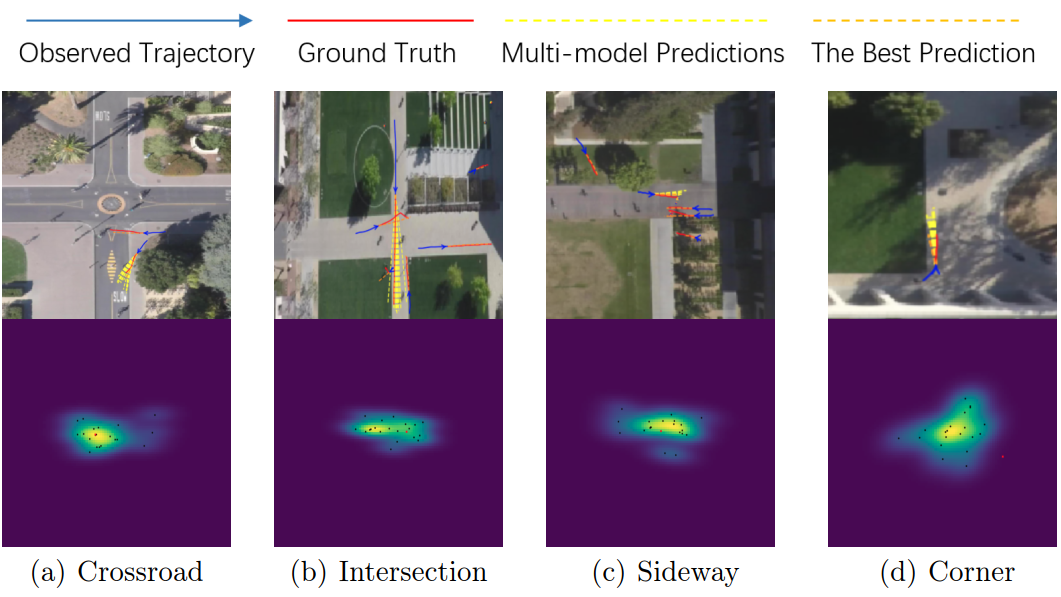 Figure 1: The visualization of multimodal predictions in four scenes. Top row: we plot multiple possible future trajectories for each agent of interest. Bottom row: we visualize the corresponding distribution heatmap of the destinations (location) via kernel density estimation. The predicted destinations and ground truth are shown as black points and red point respectively. The distribution heatmap demonstrates that our model not only provides semantically meaningful predictions, but also enjoys low uncertainty.
Figure 1: The visualization of multimodal predictions in four scenes. Top row: we plot multiple possible future trajectories for each agent of interest. Bottom row: we visualize the corresponding distribution heatmap of the destinations (location) via kernel density estimation. The predicted destinations and ground truth are shown as black points and red point respectively. The distribution heatmap demonstrates that our model not only provides semantically meaningful predictions, but also enjoys low uncertainty.
Deep Models for Understanding Human and Face Images
We investigate the task of 2D human whole-body pose estimation [2], aiming at localizing dense landmarks on the entire human body including face, hands, body, and feet as shown in Figure 2. As existing benchmarks do not have whole-body annotations, previous methods have to assemble different deep models trained independently on different datasets of the human face, hand, and body, struggling with dataset biases and large model complexity.
 Figure 2: annotation examples for face and hand keypoints.
Figure 2: annotation examples for face and hand keypoints.
We also present a simple and elegant solution for bottom-up multi-person pose estimation [3]. In the proposed method, the entire network (see Figure 3) that composes of a keypoint detection network and a grouping network is fully end-to-end trainable, and is able to flexibly deal with the grouping problem of a variable number of human instances. To achieve this, we first reformulate the grouping problem as the graph clustering problem. A graph corresponds to an image, where the nodes denote the keypoint proposals, and edges denote whether the two keypoints belong to the same person. The graph structure is adaptive to different input images instead of constructing a static graph, so it is able to dynamically group various numbers of keypoints into various numbers of human instances.
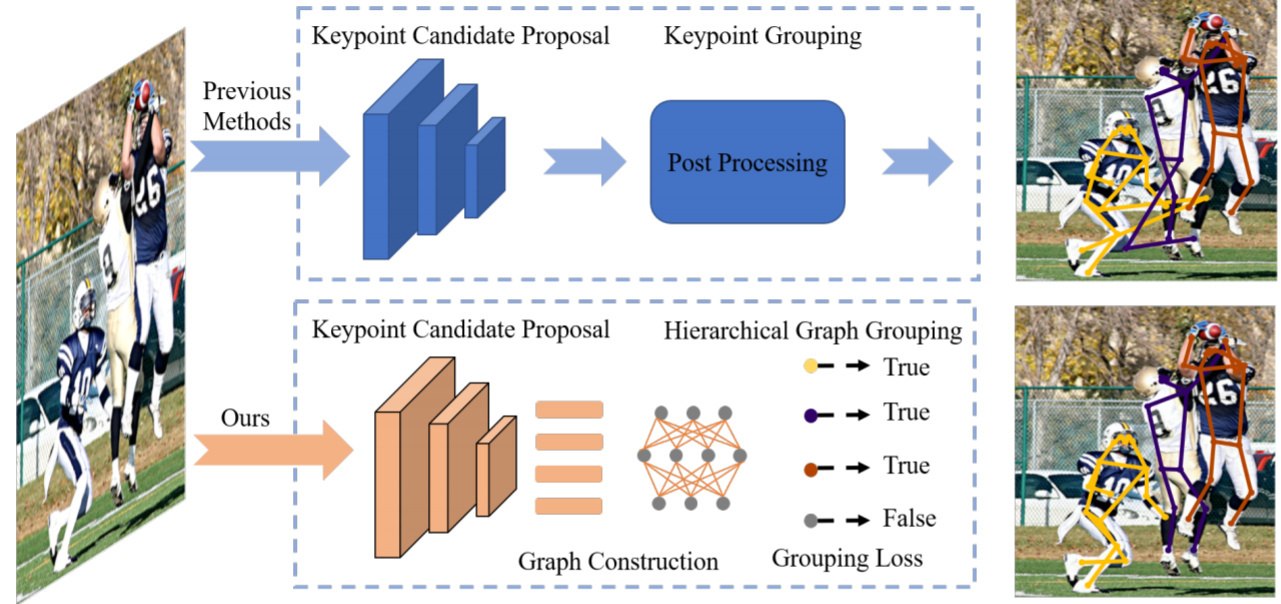 Figure 3: Hierarchical Graph Grouping embeds grouping procedure with the keypoint candidate proposal network. All modules are differentiable and can be trained end-to-end. Keypoint candidates are grouped in a multi-layer graph neural network, which enables to directly supervise the final grouping results.
Figure 3: Hierarchical Graph Grouping embeds grouping procedure with the keypoint candidate proposal network. All modules are differentiable and can be trained end-to-end. Keypoint candidates are grouped in a multi-layer graph neural network, which enables to directly supervise the final grouping results.
Another interesting system we built is to manipulate facial images [4], an important task in computer vision and computer graphic, enabling lots of applications such as automatic facial expressions and styles transfer (e.g. hairstyle, skin color) as shown in Figure 4. We present a novel framework termed MaskGAN, which aims to enable diverse and interactive face manipulation. Our key insight is that semantic masks serve as a suitable intermediate representation for flexible face manipulation with fidelity preservation. Instead of directly transforming images in the pixel space, MaskGAN learns the face manipulation process as traversing on the mask manifold, thus producing more diverse results with respect to facial components, shapes, and poses. An additional advantage of MaskGAN is that it provides users an intuitive way to specify the shape, location, and facial component categories for interactive editing.
 Figure 4: Given a target image (a), users are allowed to modify masks of the target images in (c) according to the source images (b) so that we can obtain manipulation results (d). The left shows illustrative examples from “neutral” to “smiling”, while the right shows style copy such as makeup, hair, expression, skin color, etc.
Figure 4: Given a target image (a), users are allowed to modify masks of the target images in (c) according to the source images (b) so that we can obtain manipulation results (d). The left shows illustrative examples from “neutral” to “smiling”, while the right shows style copy such as makeup, hair, expression, skin color, etc.
A Learning-to-Learn Approach
We present a new family of deep learning methods, opening up new research directions in applications, algorithms, and theory of deep neural networks. Various deep models and tasks could be revisited by these techniques. They also facilitate theoretical understanding of deep neural networks. Switchable Normalization (SN) [5] was the first meta normalization algorithm that is easily trained in a differentiable way. SN learns to combine BatchNorm (BN), InstanceNorm (IN), LayerNorm (LN), and GroupNorm (GN) for each hidden layer. It provides a new point of view for the deep learning community. SN also has theoretical value because analysing each normalization method in a unified framework is necessary before analysing their interactions in SN. Understanding existing normalization approaches are still open problems, not to mention their interactions in optimization and generalization. Moreover, a unified formulation of normalization approaches is still elusive. Sync SN synchronizes BN in SN across multiple machines and GPUs. It typically performs better than SN and existing normalizers.
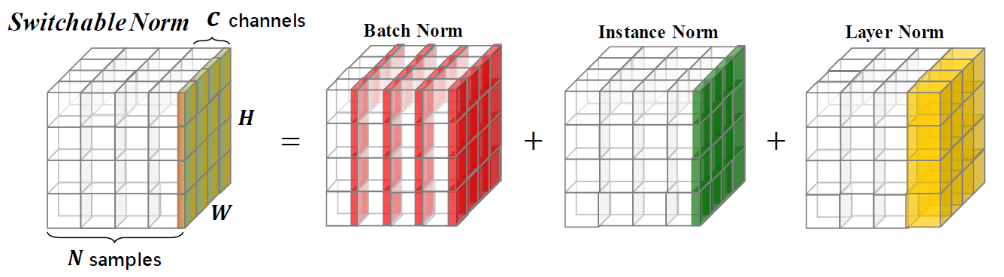 Figure 5: Switchable Normalization (SN) learns to normalize different layers by using different normalization methods.
Figure 5: Switchable Normalization (SN) learns to normalize different layers by using different normalization methods.
SN offers a new perspective in deep learning. We believe many DNNs could be re-examined with this new perspective, which therefore deserves thorough analyses. Unlike the original SN paper only visualized ratios when training converged, we study the learning dynamics and generalization regarding various hyper-parameters. We found that using hard ratios in SN improves soft ratios in SN by 0.5 top-1 classification accuracy in ImageNet, that is 76.9 v.s.77.4.
Sparse SN (SSN) [6] uses softmax function to learn importance ratios to combine normalizers, leading to redundant computations compared to a single normalizer. The importance ratios of SSN are constrained to be sparse. Unlike l1 and l0 constraints that impose difficulties in optimization, SNN turns this sparse constrained optimization problem into feed-forward computation by proposing SparsestMax, which is a sparse version of softmax. SSN inherits all benefits from SN such as applicability in various tasks and robustness to a wide range of batch sizes. SSN is guaranteed to select only one normalizer for each normalization layer, avoiding redundant computations.
We are trying to understand different normalizers theoretically [7], for example, batch normalization. This work understands convergence and generalization of BN theoretically. We analyse BN by using a basic block of neural networks, consisting of a kernel layer, a BN layer, and a nonlinear activation function. This basic network helps us understand the impacts of BN in three aspects. By viewing BN as an implicit regularizer, BN can be decomposed into population normalization (PN) and gamma decay as an explicit regularization. Learning dynamics of BN and the regularization show that training converged with large maximum and effective learning rate. Generalization of BN is explored by using statistical mechanics.
References
[1] Chaofan Tao, Qinhong Jiang, Lixin Duan, Luo Ping, Dynamic and Static Context-aware LSTM for Multi-agent Motion Prediction, European Conference on Computer Vision (ECCV), 2020
[2] Sheng Jin, Lumin Xu, Jin Xu, Can Wang, Wentao Liu, Chen Qian, Wanli Ouyang, Ping Luo, Whole-Body Human Pose Estimation in the Wild, European Conference on Computer Vision (ECCV), 2020
[3] Sheng Jin, Wentao Liu, Enze Xie, Wenhai Wang, Chen Qian, Wanli Ouyang, Ping Luo, Differentiable Hierarchical Graph Grouping for Multi-Person Pose Estimation, European Conference on Computer Vision (ECCV), 2020
[4] Cheng-Han Lee, Ziwei Liu, Lingyun Wu, Ping Luo, MaskGAN: Towards Diverse and Interactive Facial Image Manipulation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
[5] P. Luo, R. Zhang, J. Ren, Z. Peng, J. Li, Switchable normalization for learning-to-normalize deep representation, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020
[6] W. Shao, T. Meng, J. Li, R. Zhang, Y. Li, X. Wang, P. Luo, SSN: Learning sparse switchable normalization via SparsestMax, International Journal on Computer Vision (IJCV), 2020
[7] P. Luo, X. Wang, W. Shao, Z. Peng, Towards Understanding Regularization in Batch Normalization, International Conference on Learning Representation (ICLR), 2020
Contact
For more information, please contact Dr. Luo Ping (http://luoping.me/).





