
1 Introduction
Matching problems are found in many applications including assigning cars to parking slots, students to schools, customers of a booking service to hotel rooms, police cars to emergency incidents, mobile devices to WiFi routers, applicants to jobs, university applicants to degree programmes, etc. Given two sets of objects A and B (e.g., a set of cars and a set of parking slots) the goal is to find a one-to-one matching M, which satisfies a condition (e.g., stable-marriage property) or maximizes an objective function (e.g., number of cars in M, sum of distances between cars and parking slots in M). Although polynomial algorithms have been developed for matching problems considering a wide range of objectives, they all suffer from large space and time requirements if the input datasets are very large. Specifically, all these methods have at least quadratic time and space complexity, a fact that makes them inapplicable for inputs in the order of millions. On the other hand, it is not uncommon to find real-life problems of that magnitude.
We have developed scalable algorithms for matching problems, which are applicable to large-scale inputs. Our methodology is based on the use of indexing methods to guide search and the development of geometric search techniques that can derive bounds for the objective function helping towards finding a solution without exploring the whole space. This can be done by modeling the weight (cost) of each possible pair in the assignment by a function, which takes as input the two objects in the pair. We have studied a number of matching problems with different matching objective and constraints.
2 Stable Matching Problems
A matching M between two sets A and B is stable if there are no pairs (a,b) and (a′,b′) in M, such that a prefers b′ to b and b′ prefers a to a′. We have studied this problem in the context of spatial databases; in this case, an object a ∈ A prefers an object b ∈ B over another object b′∈ B iff dist(a,b) < dist(a,b′), where dist is a distance function (e.g., Euclidean distance). In [3, 4], we show that this problem is equivalent to the exclusive closest pairs problem, which generates M by iteratively computing the closest pair of objects in A × B, adding the pair to M, and removing a from A and b from B, before finding the next pair. We propose an efficient algorithm that solves this problem efficiently by exploiting spatial indexes on A and B. We also show how M can efficiently be maintained in a scenario where A and B are cars and parking slots, respectively and there are dynamic requests for parking by cars and dynamic releases of parking slots.
In [2], we investigate the efficient computation of a stable matching between user preference functions and a set of objects on which these functions apply. For example, consider a set of internships to be assigned to a set of students and assume that each student defines a linear function that totally orders the internship positions according to their attributes (e.g., nature of the job, salary, office location, etc). The objective is to obtain a 1-1 stable matching between students and jobs. Figure 1 illustrates an example with three linear preference functions F = {f1,f2,f3} (by three users), which prioritize a set of four internship positions O = {a,b,c,d} with respect to the offered salary (X) and the company’s standing (Y ). The function coefficients are normalized (i.e., they sum to 1, in order not to favor any user) and they express weights of importance on the different attributes. For example, user f1 prefers an internship of high salary over one at a company with high standing. In a stable 1-1 matching, position (i.e., object) c is assigned to preference function f1 since f1(c) = 0.68 has the highest aggregate value among all function-object pairs. Subsequently, f1 and c are removed from F and O respectively. Next, object b is assigned to f2, and, finally, user f3 takes object a.
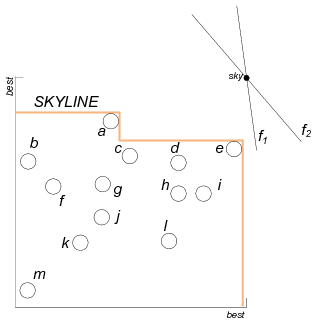
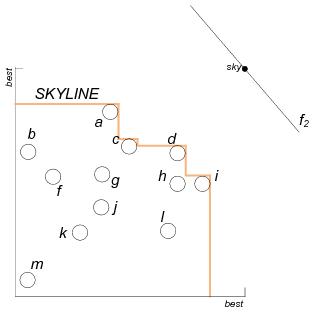
Our solution is based on a skyline computation and maintenance technique for the objects to be assigned to the preference functions. We illustrate it using an example. In Figure 2(a), we have 2 linear preference functions (shown as lines) and 13 objects (shown as 2-dimensional points). The top-1 object of each function is the first one to be met if we sweep the corresponding line from the best possible object (top-right corner of the space) towards the worst possible (origin of the axes). In the figure, e is the top-1 object for both functions. The algorithm first computes the skyline of O: Osky = {a,e}. From this fact, we know that only a and e may be the top-1 objects for f1 and f2. Therefore, it is only necessary to compare 4 object-function pairs (instead of 13 ⋅ 2 = 26) in order to find the highest f(o) score. In this example, pair (f1,e) is the first stable pair output by the algorithm. Osky is then updated to Osky = {a,c,d,i}, as shown in Figure 2(b). We then identify the next highest score pair (f2,d); this pair is reported as stable and the algorithm terminates.
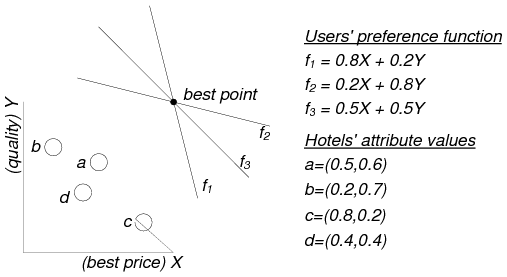
Figure 1: Internship Assignment Example
(a) Original Skyline (b) Updated Skyline
Figure 2: Example of Skyline-Based Stable Assignment
3 Optimal Assignment based on Spatial Distances
Given a point set P of customers (e.g., WiFi receivers) and a point set Q of service providers (e.g., wireless access points), where each q ∈ Q has a capacity q.k, the capacity constrained assignment (CCA) is a matching M ⊆ Q × P such that (i) each point q ∈ Q (p ∈ P) appears at most k times (at most once) in M, (ii) the size of M is maximized (i.e., it comprises min{|P|,∑ q∈Qq.k} pairs), and (iii) the total assignment cost (i.e., the sum of Euclidean distances within all pairs) is minimized. Thus, the CCA problem is to identify the assignment with the optimal overall quality; intuitively, the quality of q’s service to p in a given (q,p) pair is anti-proportional to their distance. Although a min-cost max-flow algorithm can be used to solve this problem, it requires the complete distance-based bipartite graph between Q and P. For large spatial datasets, this graph is expensive to compute and it may be too large to fit in main memory. Our solution [7, 6] creates the distance-based bipartite graph incrementally and computes the result without having to generate the entire graph, by employing novel edge-pruning strategies, based on the spatial properties of the problem. Additionally, we develop incremental techniques that maintain an optimal assignment (in the presence of updates) with a processing cost several times lower than CCA re-computation from scratch. Finally, we present approximate (i.e., suboptimal) CCA solutions that provide a tunable trade-off between result accuracy and computation cost, abiding by theoretical quality guarantees. In [5], we study a version of the problem where the feasible edges in the assignment are constrained by spatial distance (i.e., providers can serve only customers within a given spatial range around them) and the objective is to maintain the optimal assignment while the customers move. In [1], we demonstrate how our solution to the optimal assignment problem (proposed in [6]) can be used to accelerate image similarity search by orders of magnitude.
Grant Support
Algorithms for Large-Scale Matching Problems (RGC GRF, Ref: HKU 715509E), HKD 460,795.
References
- Y. Tang, L. H. U, Y. Cai, N. Mamoulis, and R. Cheng. Earth mover’s distance based similarity search at scale. Proceedings of the VLDB Endowment, 7(4):313–324, 2013.
- L. H. U, N. Mamoulis, and K. Mouratidis. A fair assignment algorithm for multiple preference queries. Proceedings of the VLDB Endowment, 2(1):1054–1065, 2009.
- L. H. U, N. Mamoulis, and M. L. Yiu. Continuous monitoring of exclusive closest pairs. In Advances in Spatial and Temporal Databases, 10th International Symposium (SSTD), pages 1–19, 2007.
- L. H. U, N. Mamoulis, and M. L. Yiu. Computation and monitoring of exclusive closest pairs. IEEE Transactions on Knowledge and Data Engineering, 20(12):1641–1654, 2008.
- L. H. U, K. Mouratidis, and N. Mamoulis. Continuous spatial assignment of moving users. VLDB Journal, 19(2):141–160, 2010.
- L. H. U, K. Mouratidis, M. L. Yiu, and N. Mamoulis. Optimal matching between spatial datasets under capacity constraints. ACM Transactions on Database Systems, 35(2), 2010.
- L. H. U, M. L. Yiu, K. Mouratidis, and N. Mamoulis. Capacity constrained assignment in spatial databases. In SIGMOD Conference, pages 15–28, 2008.